Inside Meta AI’s New Method to Build LLMs that Think Before they Speak
Thought Preference Optimization could be the new foundation for “Thinking LLMs”.
I recently started an AI-focused educational newsletter, that already has over 170,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
Reasoning is one of the most interesting areas of research in the world of foundation models and one that has been accelerated since the release of GPT-o1. The more specific trend is to develop foundation models that can “reason” before producing an output. This concept draws inspiration from how humans tackle complex problems, taking time to ponder and strategize before arriving at an answer. Research in the area of planning and reasoning is being tracked very closely as it can represent the next breakthrough in generative AI. This is the area of a recent research paper from Meta AI which explores a novel technique called Thought Preference Optimization (TPO). This is one of the most interesting papers in reasoning I’ve recently and, today, I would like to unpack the core ideas, examine experimental results, and consider the potential impact of this approach on the future of generative AI.
The Need for Thought in LLMs
Traditional LLMs, despite their remarkable abilities, operate on a fixed compute budget, meaning they allocate the same amount of processing power to generating the first response token, regardless of the instruction’s complexity. This approach falls short when faced with tasks requiring deep reasoning and planning. Just like a human wrestling with a challenging puzzle, LLMs can benefit from taking a step back and “thinking” before diving into a response.
This “thinking” process can take various forms, including generating internal text that represents the model’s thought process. Chain-of-Thought (CoT) prompting is a popular technique that encourages LLMs to articulate their reasoning steps. However, CoT has mainly proven effective in math and logic-based tasks, showing limited benefits in other domains.
In the TPO paper, Meta AI argues that “thinking” should have broader utility, extending beyond the realms of math and logic. Imagine an LLM tasked with writing a creative story. Internal thoughts could help it plan the narrative structure, develop characters, and craft compelling dialogue. Similarly, “thinking” could aid in understanding complex user instructions, leading to more accurate and relevant responses.

Enter Thought Preference Optimization (TPO): Training LLMs to Think Without Explicit Supervision
Training LLMs to think effectively poses a significant challenge due to the lack of labeled thought data. Human-written text often omits internal thought processes, making it difficult to directly supervise a model’s thinking ability. This is where TPO comes in, offering a clever solution that leverages existing instruction-tuned LLMs and reward models (also known as judges) to guide the development of thinking skills without needing explicit thought data.
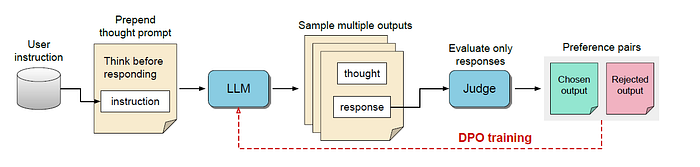
Here’s how TPO works:
- Prompting for Thoughts: The LLM is instructed to generate an output sequence consisting of two parts:
- Thought part: Internal reflections or reasoning steps, not shown to the user.
- Response part: The actual answer presented to the user.
Two types of thought prompts are explored:
- Generic: Provides general instructions to write down the thought process (e.g., “Think before responding”).
- Specific: Guides the model towards a particular format, like drafting and evaluating a response.
- Evaluating Responses Only: The response part of multiple outputs is fed to a standard judge model, which evaluates their quality without considering the thoughts behind them. This eliminates the need for a specialized judge capable of understanding internal thoughts.
- Preference Optimization: Using techniques like Direct Preference Optimization (DPO), the model is trained to generate thoughts that lead to better-scoring responses. This iterative process gradually refines the thinking ability, even without direct supervision on the thought process itself.
- Length Control: A mechanism is implemented to mitigate the tendency of some judges to favor longer responses. This ensures that the model’s responses remain concise and relevant.
TPO in Action: Experimental Results and Analysis
The researchers tested TPO using an 8B parameter Llama-3-Instruct model and evaluated its performance on benchmarks for general instruction following, such as AlpacaEval and Arena-Hard. These benchmarks utilize GPT-4 as a judge to assess the quality of responses.
- Thinking Improves Performance: After several training iterations, TPO consistently outperformed the direct baseline (the same seed model without explicit thinking), demonstrating significant gains on both benchmarks.
- Benefits Beyond Reasoning: Interestingly, TPO not only improved performance on reasoning-heavy categories but also showed benefits in domains like language translation, marketing, and health. This suggests that thinking can have a positive impact on a wider range of tasks than previously thought.
- Evolution of Thoughts: Analysis revealed that the model learned to shorten and condense its thoughts over time, indicating increasing efficiency in its internal reasoning processes.

Intriguing Observations and Further Exploration
Beyond the quantitative results, the paper highlights some fascinating observations that warrant further investigation:
- Choice of Thought Prompts: Different types of thought prompts (generic vs. specific) influenced the content and length of the generated thoughts. Exploring a more diverse set of prompts could unlock new ways for the model to think and reason.
- Math Performance Degradation: While TPO excelled in general instruction following, it showed decreased performance on a math-focused dataset (GSM8K). This suggests that the current training setup might not be ideal for math-heavy tasks, and further adaptations might be needed to enhance performance in these areas.
- Controlling Thought Length: The lack of explicit control over the number of thought tokens poses a potential challenge in terms of computational cost and efficiency. Future research could explore mechanisms to adjust the “depth” of thinking based on task complexity.
TPO and the Future of AI: Towards More Thoughtful and Versatile LLMs
The development of TPO represents an important step towards creating more sophisticated and adaptable LLMs. The ability to engage in internal thought processes opens up a world of possibilities, allowing models to:
- Tackle Complex Problems: By incorporating reasoning and planning into their operations, Thinking LLMs can effectively address challenges that require multi-step solutions.
- Exhibit Greater Versatility: TPO’s effectiveness across various domains hints at the potential for Thinking LLMs to excel in a wider array of tasks, moving beyond the limitations of traditional approaches.
- Enhance Explainability: Making thoughts explicit provides a window into the model’s internal workings, facilitating better understanding and analysis of its decision-making processes.
As the field continues to advance, we can expect to see even more creative and effective methods for teaching LLMs to think. The quest for Thinking LLMs promises to unlock new levels of intelligence and capability in AI, paving the way for machines that can truly understand and respond to the complexities of the world around us.
